TsurugiとRSA
TsurugiとRSA
2023/12現在、Tsurugiは単ノード稼働の制約があるので、次のフェーズとして複数ノードでの稼働を目指しています。Tsurugiは直接の操作対象データのindex treeをメモリーにもつRDBであり、単ノードでのメモリー限界がパフォーマンス限界になります。複数ノードにまたがるメモリー・クラスターでの透過的な稼働をTsurugiの次の目標としています。想定されているアーキテクチャはRack Scale Architecture(以下RSA)になります。
RSAについては、まずこのポストがスタート地点。
https://okachimachiorz.hatenablog.com/entry/20151225/1451028992
これは2015年なので、8年前のエントリーになります。概ねコンセプトは変わっていません。(8年前は誰かがつくるだろうとおもっていたけど、まさか自分がやる羽目になるとは思いませんでした。)
まずはこのポストのreviewからですが・・・現在でもそれほど変わっていないところもあれば、変わっている部分もあります。
1.対象データサイズ
それほどの大規模クラスターは日本企業では必要ない、という8年前に比べてどうか現在はどうか?というと、たしかにPBサイズのクラスターは珍しくはなくなりました。とはいえ、一般的な企業でそのサイズのデータを保持・運用している企業はやはり現在でも少数派です。特に、ここ数年はクラウドもかなりの高コストになりつつあり、PBクラスの大規模データをクラウドで運用し、コストメリットを取るのは国内企業では簡単ではありません。
実際、ユーザベースで見た時に取り扱うデータサイズは増加したのか?という点では、おそらくちゃんとしたデータありませんが、体感としては、分析系については普通に5-10倍程度には増えた感じです。一方で、基幹系・勘定系については、1.2-1.5倍程度で、倍にもなっていない、という印象です。
概ね、一般的な企業のシステムのデータサイズは、100GBから10Tの間ぐらいで、さすがに単ノードでは足らないがハーフラック程度のサーバ数でそこそこに収まる、という状況に見えます。
2.H/Wのスペックから
RSAの定義については、「複数のノードを“高密度”にRack内部で組み上げて凝縮性をあげて、ラックベースの一つのコンピュータと見なすアーキテクチャ」で変わっていません。100コアマシーンがそれほど珍しくない現状では、“Rack内部で、総計1000コア+10TB-DRAMのサーバ・クラスター”はそれほど特殊でもないH/W環境と言えるでしょう。この8年でRSAの環境は身近になったとはいえます。
3.RSAの内部構造について
8年前のポストでは、RSAの特長として、RDMAとNVMを挙げています。まず、NVMですが、残念ながら普及の見通しは立たない状態になってしまいました。NVMは、やはり遅延がDRAMに足らず、またbyte単価がSSDには勝てない、という中途半端な状況だったのが最後まで普及に影響したというところでしょう。Intelの撤収はほぼ全面的なギブアップに見えます。
一方のRDMAですが、この8年で一般的になった、というところではないでしょうか。DCによってはかなり導入実績も出ているようです。特にHPCではもうかなり一般的なようですね。
下回りはEtherかIBで、直接のバス結合はちょっと下火感があって、まぁ割と一般的なバスで利用しましょう、ということになり、プロトコルはRoceV2か、iWARPかに現時点では収斂しつつあります。結局のところは、NIC経由はいいとして、カーネル・バイパスをするか?しないか?というところに還元されそうな気配です。
普通に考えればSoCでCPUから処理をオフロードしたほうが、圧倒的にコストが安いはずですが、豈図らんや、特にヘテロなワークロードではRoce等の設定やらドライバーの出来やらで、なんやら奇々怪々な不安定さがでる一方で、普通にスタック通したほうがクリーンで、存外パフォーマンスが出てしまう現状もあるようです。導入期あるあるではあるのですが、この辺どーにかならないのでしょうか・・・
DB陣営としては「透過的であることは正義」とばかりに、できるだけ論理層は分離するが吉、のデザインで、とりあえず低遅延なら下はなんでもよいですの強行突破ということになりそうな気配です。
また一方で、ここにきて、CXLが本命とばかりにドヤ顔状態でして、PCIe5の登場で出たばっかりのPCIe4があっという間に陳腐化の憂き目と、煽りをくらって「やっとできたもんねスマートNIC」が、これまたすごい勢いで次世代に移行とか、・・・いや、つくる方は投資回収できないのでは?という懸念もありますが。
総じて「低遅延でのRack内部・Rack間でのサーバ接続」は、ものすごく進歩しつつある、現在もっともホットなインフラの焦点の一つであることは間違いないでしょう。その意味でRSAをS/Wスタックとして、どうしていくか?を掘り下げるにはちょうどいい時期です。この辺りは、ミドルがなんとかするのが筋でしょう。選択肢は異様にあるように見えて、実は使えるのは2-3しかない、なんてのは日常茶飯事なんで。
◆TsurugiではRSAで何をするつもりなのか?
大きくは二つになります。replication/partitioningと分散トランザクションです。両者の違いはserialization spaceが単一かどうかです。前者では単一で、後者では複数になります。
1. replication/partitioning
replicationとpartitioning(disjoint replication)は、A) 同じデータをもつreplicationと、B) 同じデータを持たないpartitioningと、C) その混合のpartial replicationの3種類を想定しています。これら三つの違いはデータを各ノードに分散させる際の「重なり度合い」の違いになります。
A) replication

同じデータを複数の物理ノードにもつことで、可用性を確保します。複数ノードのメモリー・クラスターで同じデータを持ち、処理はすべてtransactionとします。すなわち、partial writeは発生させません。クラスター内で単一のserialization spaceを持ちます。commit levelはpropagatedになり、クライアントに対しては“必ず所定の複数のノードで同じデータが存在できた”場合にcommitが返ります。
必要な合意メカニズムは単純に静的なノード構成についてのみとし、log replicaについては考慮しません。シンプルかつ高速なアルゴリズムを利用します。(できれば作りたくないけど、たぶん作る羽目になりそう。極低遅延での余計なことを一切しないクラスターノード管理ミドルは実はありそうでないようです。大抵は余計なことをやる上に高遅延前提に見えます)
まったく同じデータを複数ノードのメモリー上に常にもち、サーバダウン時の可用性確保を極めて高速に行うことを企図しています。
B) partitioning
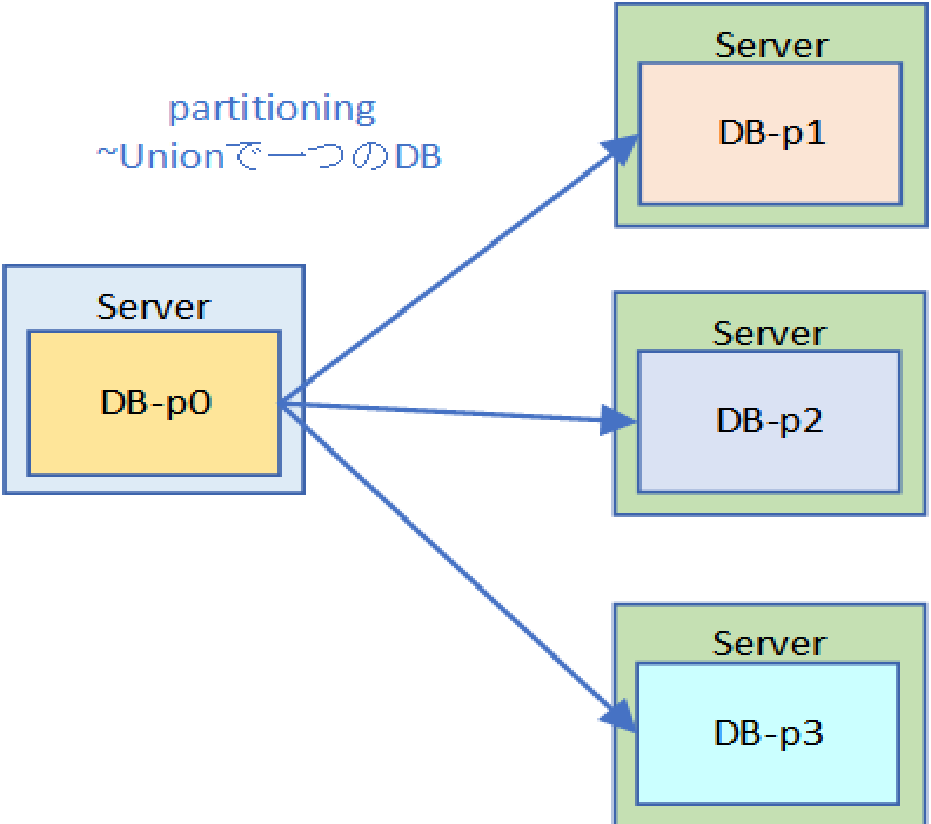
個々のデータを複数の物理ノードに分散させて、スケールアウトを確保します。複数ノードで同じデータを持つことはなく、複数ノードのデータのユニオンがDBそのものになります。当然ですが、A)と同様に処理はすべてtransactionになり、クラスター内部で単一のserialization spaceを持ちます。
取り扱うデータ量が増加した場合に、そのまま物理ノードを追加することで対応できることを企図しています。ただし、replicationがないので、単一ノードへの書き込みが失敗した段階で、DBへの書き込み失敗となります。すなわち、追加ノード分だけSPoFが増えることになります。
C) partial replication

partitioningとreplicationの「合わせ技」になります。各partitionの単位で、replicationを行います。replicaが存在するため、partitioningを行いながら高可用性を確保することが可能になります。B)だけでは可用性に難がある一方で、A)だけではスケールアウトに問題があります。したがって理想はその組み合わせということになります。
2.分散トランザクション
これは“複数”の”単一のTsurugi”にまたがって処理を行うときに、globalにserialization orderをとるという処理になります。この時の“単一のTsurugi”は物理サーバ数は限定しません。単一サーバであったり、複数サーバであっても構いませんが、いずれにしろserialization spaceは単一とします(なお、この時の論理境界をSphere of Control (SoC)と呼んでいます。要するに複数のSoCを処理するということです)。
この単一のserialization spaceを複数にまたがって、transactionを実行することをTsurugiでは分散トランザクションと定義しています。(すなわちTsurugiでは分散トランザクションは物理的なものではありません。)この辺りを目指していきます。
◆道具立てについて
replication/partitioningにしろ、分散トランザクションにしろ、いずれしても「高密度低遅延分散システム」です。この分散システムの論理インフラとして、Epoch based synchronizationをレイヤーとして作成し、同期インフラとします。時刻同期はH/W(物理time server)で行う予定です。いまのところの利用プロトコルはPTPっぽいです。
そもそもTsurugiは分散DBを企図してつくられています。Tsurugi自体がEpochベースなので、Epoch based synchronizationは、この延長線で行けますし、transaction処理はread-lock free / write lock-freeなので、各ノードでlockを取らずに処理を“渡り歩く”ことができます。このアーキテクチャは低遅延分散DBには極めて有利です。
リリース順としては、今のところはreplicationがもっとも先にプロダクションでリリースされ、次にpartitionが試験的に、プロダクションとしてはC)の混合を一緒にリリースされると思います、というか、この辺はもう想像ですね。分散トランザクションについては、現時点ではあくまでプロトタイプを想定しています。
また、partitioningについては分散Index treeを想定しています。DHTでは低遅延要求環境では、特にrange scanやfull scanで簡単にN/Wが(最適化を行っても)飽和する可能性が高いので、今のところは考えていません。
◆雑感
RSAという言い方自体は、多分に物理的な制約の話(Rack内部=低遅延)でしかないので、これを論理的な枠組として捉え直した場合は、最後は遅延限界の話に還元されるような気もしています。あくまでTsurugi、というよりもECCベースでの分散クラスター、が前提の話ではありますが。
仮にRackを跨いだN/W構成の遅延が、Rack内部と変わらないのであれば、複数のRackから構成されるRSAというのも勿論可能です。これはおそらく今後はDC内部・DC間にまで拡大することが可能で、この場合はDC間を跨いだ「RSA」ということになり、Rackの意味はあまりないですね。では、どこまで拡大するの?って話はあって・・・
https://dsstation.sakura.ne.jp/report/misc/chien_nw.html
なんてので計算すると(合ってんのかこれ)1000kmで片側6.5msです。すでにepoch=3msとして、物理的に成立しません。epoch=3~1msとすれば、往復で考えれば、100kmというのは一つの「カテゴリー」になるでしょう。その意味ではTsurugiが参加するPETRAにしろ、NTTのIOWNしろ、あるいは都市OS的なものを含めて100km圏というのは、すくなくともRSA的なアーキテクチャから見た場合は、一つの基準になると見ています。Tsurugiとしてはこの辺は真っ向勝負にいくもんね、ということで。
なお、100km以下であれば、サーバ内部の話になるので、これはIntel規格のバスの勝負の話でTsurugiとしては単ノードでどこまで切り詰めるか?という話題になり、逆に100km超であれば、どう転んでもGAFAMをはじめとするビッククラウドベンダーのDBの方が最適のはずなので、Tsurugiとしてはやるだけ無駄、という意識でござる。やったところで非同期のlog-shipになるので、普通に分散合意の悪夢再びかと。この辺は遅延とのトレードオフの選択か、または適当にRaftっぽいいつものヤツでお茶を濁すということになる気もします。個人的にいずれにしてもメンバーシップ管理とpartial writeの問題は「べつべつに」片付けた方がイイと思ってはいます。
そんな感じでございます。